



For Whalebone, getting fresh information on current threats is crucial. One source of such information is Twitter accounts of threat experts who post threats that they have come across. These tweets usually identify current threats, which makes their contents extremely valuable. Crucially, the data is neither structured nor harmonized, meaning one must use heuristic reasoning ("decode" them back to proper form) to be able to extract it.In this article, we aim to describe how we went about extracting the data while showing different challenges we faced during the implementation. Besides, we will show how useful this data is in protecting the network.There are two ways in which tweeters (Twitter users from the security community) share threat intelligence data, so called "indicators of compromise" (later on referred as "IOCs"). In our case, IOCs are malicious web addresses, posted either in a link to pastebin.com or in the body of the tweet itself, in which case they are usually protected against opening as described below.
How do tweeters share data about threats?
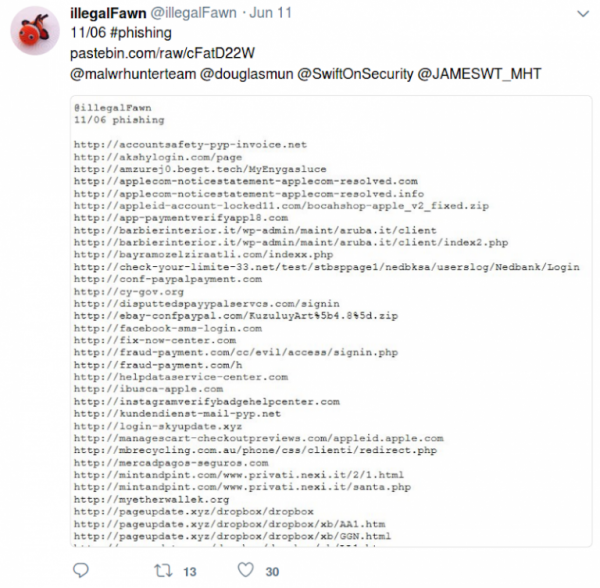
The former could easily reduced to the latter. We implemented a function that connects to those links and extracts e-text, from which IOCs can then be extracted by similar methods as from the main body of the text, but with the simplification that obfuscation usually doesn't take place. At the end of the day, however, not all tweeters post URLs on pastebin and some post hashes and other information about threats. To take care of such cases, we follow URLs only for specified Twitter accounts.Extracting data from the tweet body seemed like a formidable task, since there is no straightforward way of telling which URL is a true IOC and which is just a legitimate address that the tweeter could have posted. Fortunately, IOCs are marked by an important feature - they are obfuscated, so that Twitter doesn't convert them into clickable links and people do not accidentally end up on malicious websites.This feature of IOCs enabled us to filter out legitimate links - simply exclude all the links that are clickable (which is done by blacklisting t.co domain, as twitter sends all links through its servers).
Removing obfuscation
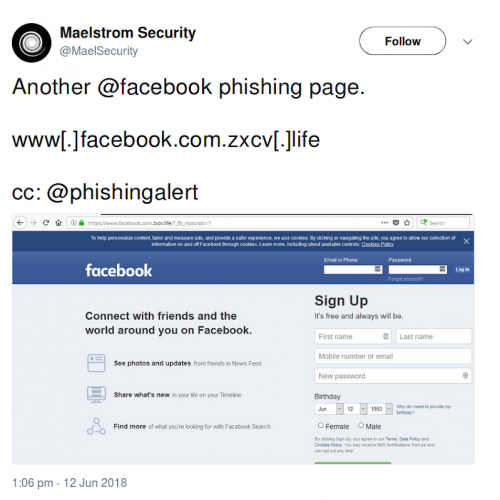
Having ignored the t.co domain, all that is left in a raw tweet are obfuscated IOCs. The obfuscation methods vary, but there are not too many and most work by direct substitution. Common examples include ‘abd[.]com’ and ‘hxxp://el_karls.com’:
- The first example contains the most common substitution: '.' for '[.]'. Such obfuscation can be undone by simply substituting '[.]' for '.', leaving valid URLs which can then be parsed.
- The second example contains another common method: the replacement of http by hxxp. Dealing with such cases is even easier - we simply ignore the protocol in the later stages of parsing the text.
It turns out that for most tweeters, we could simply revert the substitutions made during obfuscation by a mere substitute command. This makes it really simple to start parsing a new twitter feed – plainly collect the tweets from that tweet and add the substitutions required to revert obfuscation to a list in the config file. After performing substitutions, we have URLs matching a URL regex ignoring the protocol (to account for ‘hxxp’). Matching against this regex and then checking with get_tld whether the matched text is indeed a valid domain is all that is left to do.In a production environment, we implemented this algorithm with a configuration file containing 30 tweeters and 6 substitutions. Pastebin was followed in about 10 of them.This results in about 2500 IOCs weekly flowing into our system, and since deployment in April, we have already recorded 3000 incidents involving these IOCs.While useful, this model is still rather crude and doesn’t make use of all the information available in the tweets. For example, most tweeters also include the classification of the shared IOCs in their tweets (see example tweets, which both include this information), which is a useful bit of information and future challenge for us to get it into Whalebone.
Author: Kryštof Kolář